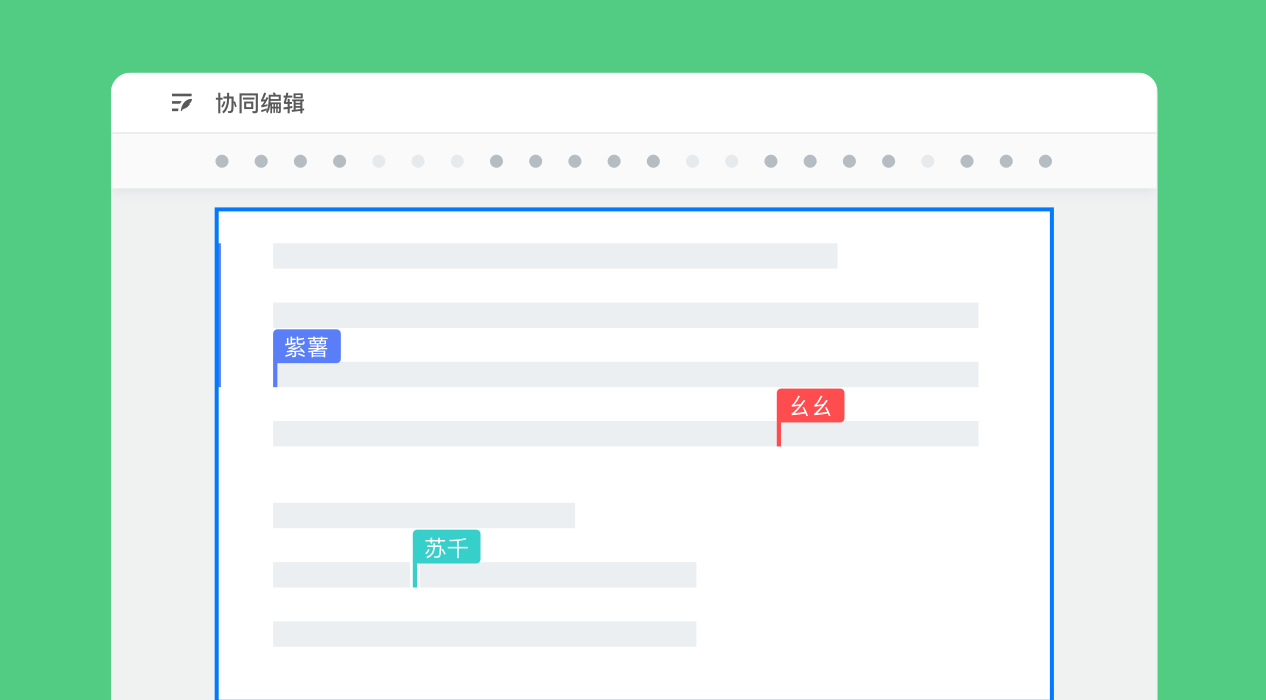
引言
如何设计和实现一个多用户场景下的文档编辑器?
如果的只是单用户的场景,其实可以很简单地实现,只需要一个 <TextArea /> 输入框就够了。至于富文本的实现,可以直接渲染Markdown,那么文档的数据只需要朴素的文本格式保存md string就行了。不涉及状态同步,没有复杂数据模型,也不会产生任何冲突。
但是在多用户的场景下,一篇文档可能被多个用户分时或者同时编辑,而且文档也可能有排版需求。编辑器如何支持多用户编辑场景?文档的数据模型又该如何设计?多用户编辑产生的冲突又如何解决?
第一个问题,编辑器要支持多用户编辑场景,就是要记录和同步每个用户修改操作 (Operation-based record) 或每个用户修改后的文档状态 (State-based record),亦或者二者兼有之。
第二个问题,文档的数据模型目前有两种主流的富文本模型,基于操作流的Delta和基于JSON的Slate:
Delta 数据模型
Quill 编辑器显示一段文字
它定义三种操作(insert、retain、delete),编辑器产生的每一个操作记录都保存了对应的操作数据,然后用一些列的操作表达富文本内容,操作列表即最终的结果。
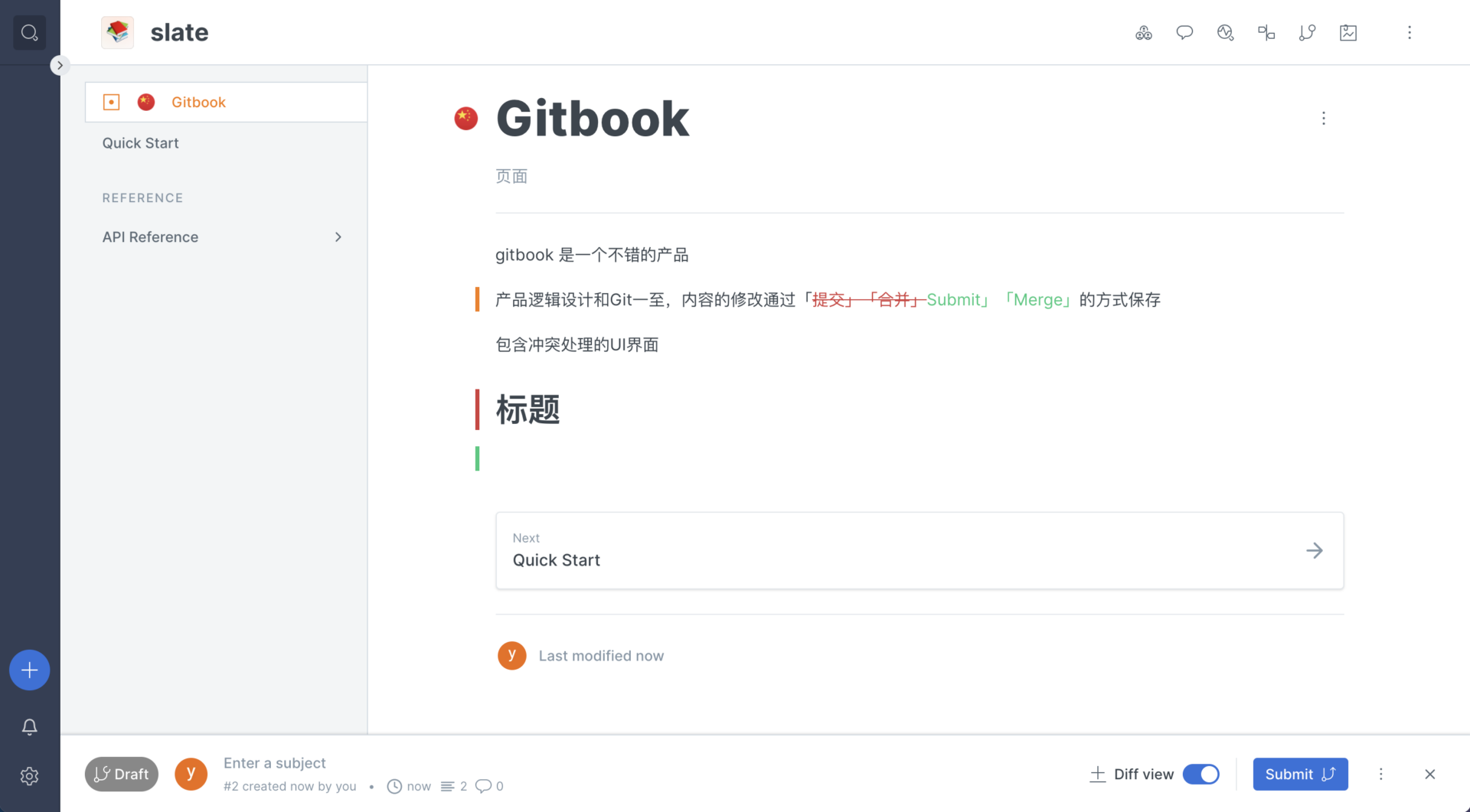
Slate 数据模型(JSON)
编辑器中有一个图片类型的节点
对应的数据结构:
属性修改操作:
我们可以看出虽然 Delta 和 Slate 数据的表现形式不同,但是他们都有一个共同点,就是针对数据的修改都可以由操作对象表达,这个操作对象可以在网络中传输,实现基于操作的内容更新,这个是协同编辑的一个基础。
第三个问题,多用户编辑的场景下,用户间的操作不可避免地会产生冲突,如何解决?主流有三种方式:
- 悲观锁,同一时间只允许一个用户持有锁可编辑。转换为单用户编辑场景。代表:老版本Office
- git方式,把无法自动merge的冲突扔给用户自行手动合并。代表:Gitbook
- 自动合并冲突(协同编辑)。使用某种协调机制或算法,努力满足每个冲突操作的意图,并同步并保持文档最后的状态一致。代表:钉钉文档、新版语雀、腾讯文档、WPS云协作等。

目前,协作编辑中处理冲突有两种主流算法:OT和CRDT。接下来我会简单介绍目前得到主流应用的OT,并详细介绍新兴且很有可能成为未来发展方向的CRDT的算法的主要思想。
OT与CRDT
首先来看协同编辑中,冲突产生的几个主要场景:
- 脏路径
假如编辑器中有三个段落,如下图所示
这里用数组简单模拟上面的三个段落,下图展示了两个用户同时对数据修改产生的操作序列
可以看到左边插入的段落「Testhub」插入位置是错误的,因为插入Access的操作使得后续插入Testhub的位置被污染了。
2. 并发冲突
以上面图片数据结构为例,两个用户同时对align属性进行修改:
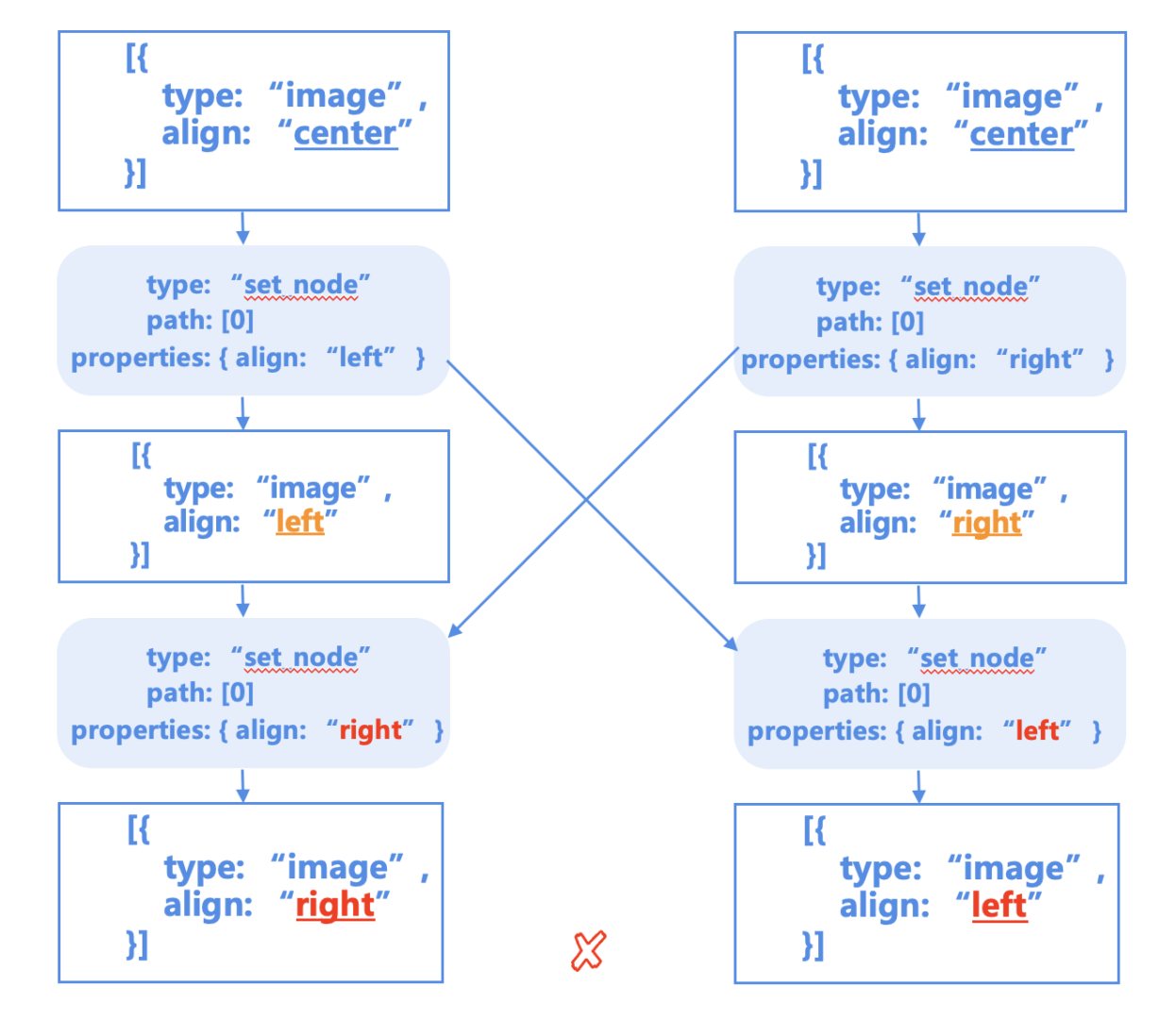
最后每个用户产生了不同的结果,造成数据不一致的问题。
3. undo/redo 撤回重做
这个场景更为复杂。以脏路径下的场景为例,我们从右边用户的视角来看:
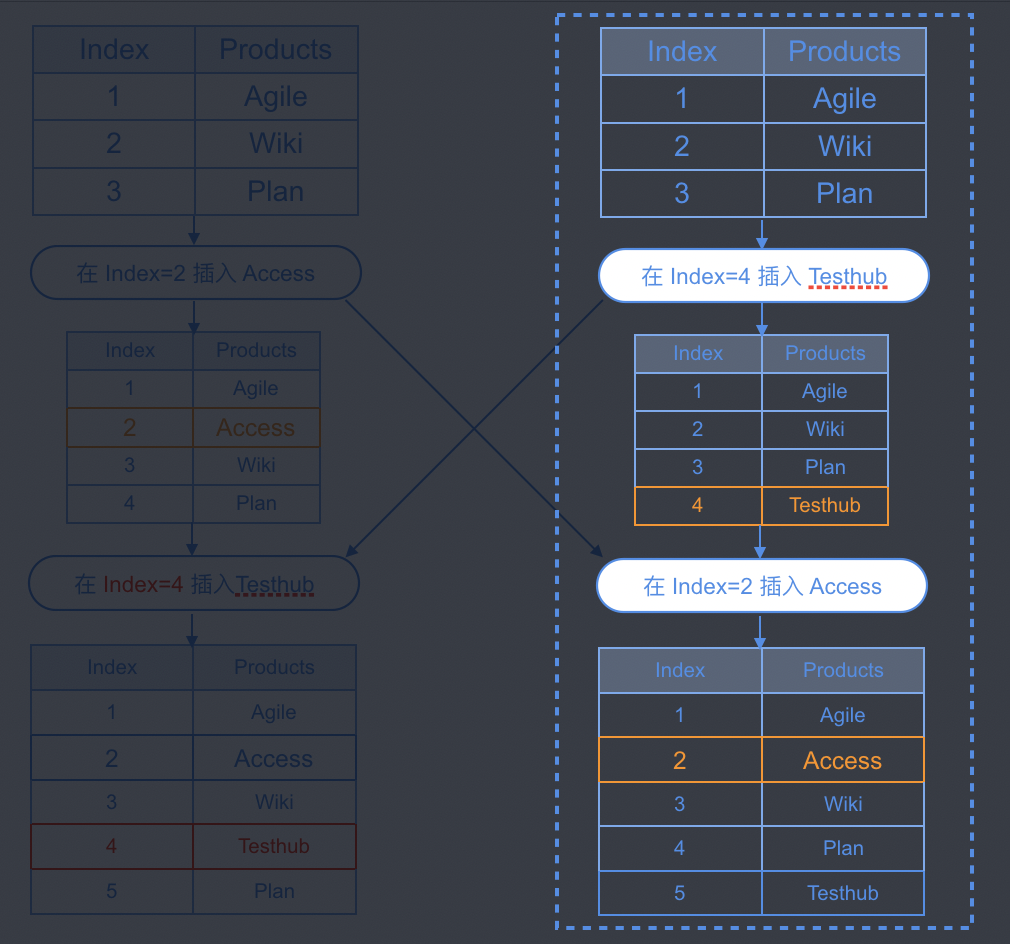
右边用户此时发起撤回操作,逻辑上说应撤回文档最后一条操作(在Index=2插入Access),但从用户习惯上说只应撤回自己的操作(在Index=4插入Testhub)。
如果按照使用习惯只能撤回自己的操作,问题又来了,右边用户当初的操作是在Index=4插入Testhub,那撤回的话应该做一个逆操作:删除 Index=4 位置的节点。结果把Plan给删掉了。这本质上也属于脏路径问题。
除了这种「脏路径」问题,「并发冲突」问题也会以类似的方式出现,具体的逻辑就不再详细分析了。
学术界针对并发冲突问题,提出了两种数据一致性算法:
系统不需要是正确的,它只需要保持一致,并且需要努力保持你的意图。
1. OT (Operational Transformation) 操作转换
OT的核心思想是对用户协同编辑中产生的并发操作进行转换,通过转换对其中产生的 并发冲突 和 脏路径 进行修正,然后把修正后的操作重新应用到文档中,保证最终数据一致性。
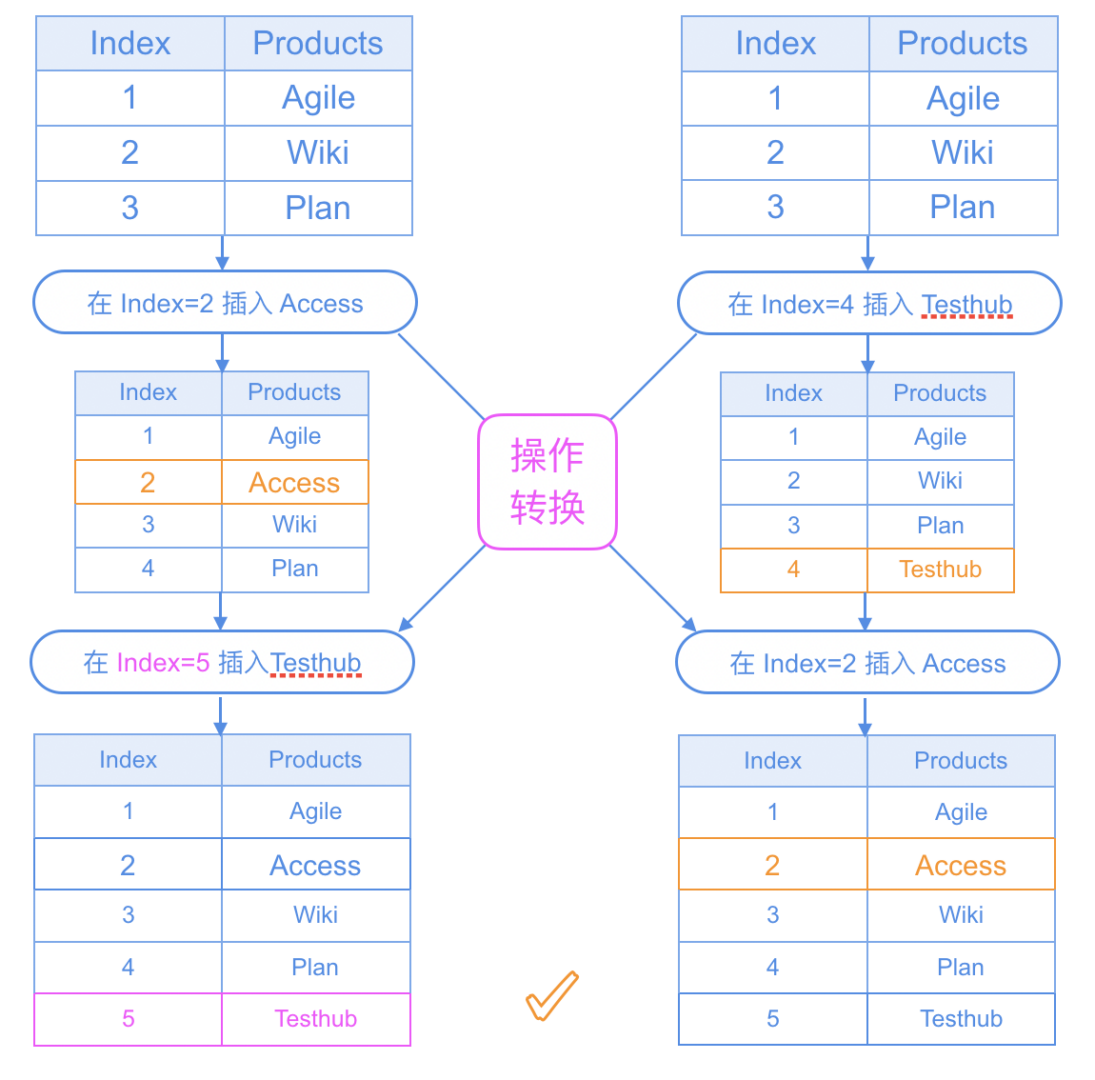
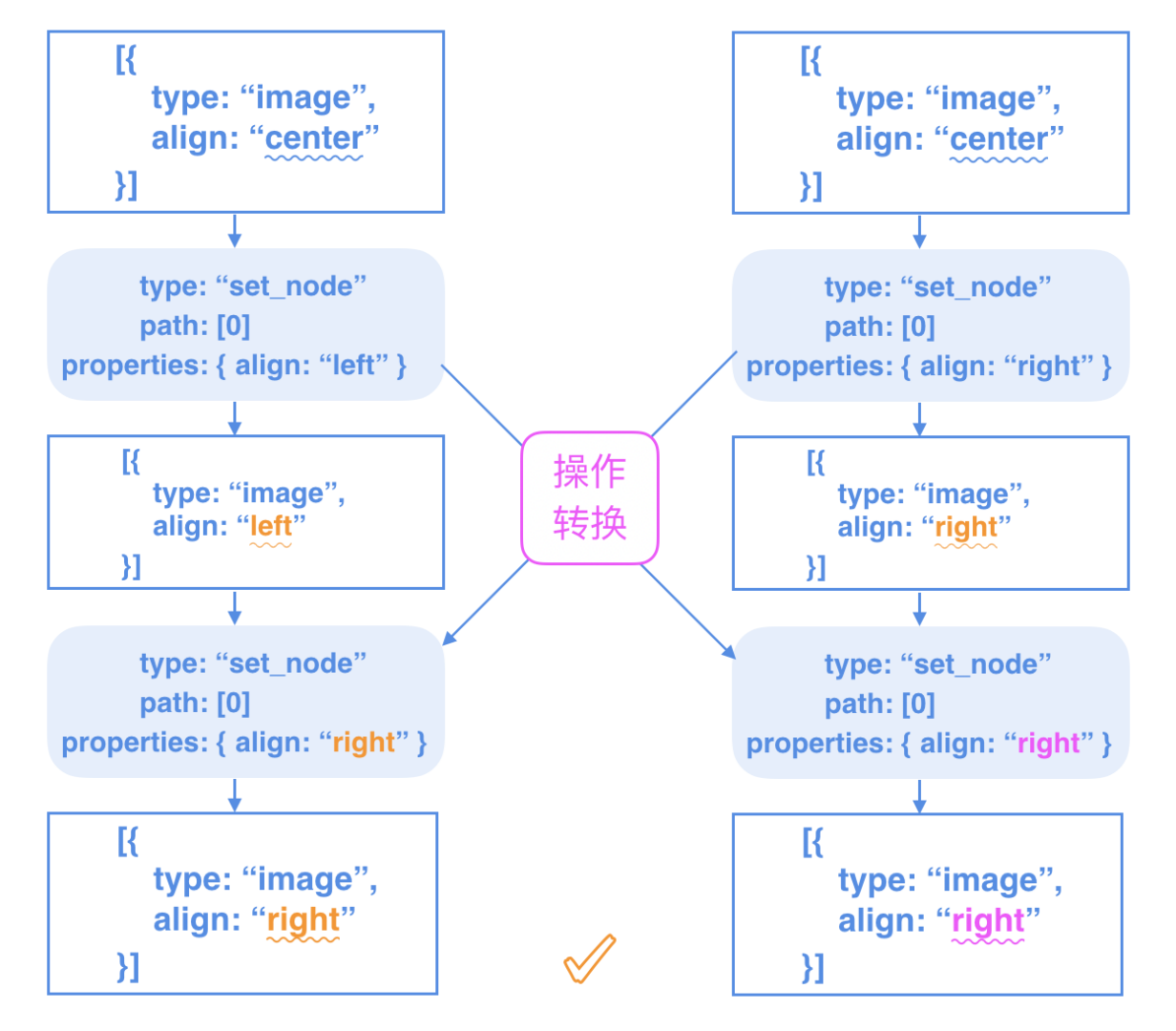
关键词:仲裁官(中心服务器)、直接修改/转换用户操作、保证最后状态一致。
2. CRDT (Conflict-free Replicated Data Type) 无冲突复制数据类型
通过设计一种数据结构,在不依赖中心服务器仲裁的情况下,每个client直接互相分发这种数据结构,自行衍生出一致的最终状态,解决分布式系统的最终一致性问题。其中比较系统完善、基于操作的CRDT算法 (Operation-based CRDT) 实现是YATA。
| 优势 | 劣势 | |
| OT | – 更容易保留用户意图 – 不影响文档体积 – 更成熟,被广泛运用 |
– 依赖中心化服务器 – 不支持离线编辑 – 不同数据模型需要单独实现其OT算法 |
| CRDT | – 去中心化 – 天然支持离线编辑 – 算法简单、数据模型通用 |
– 某些情况下会背离用户意图 – 内存开销比较大 – 相对年轻,尚未得到广泛运用 |
YATA算法思想
CRDT-YATA的核心思想不在于解决冲突,而在于构造一种数据结构来避免冲突。
数据结构
每个我们看到的文档都是由一系列操作的结果衍生出来的。
YATA从一开始就为在文档中创建的每个字符构造一个特殊的数据结构Item,Item之间以双向链表的形式连接在一起;每个 Item都唯一地记录了某次用户的操作信息、前驱Item和后继Item、并有着独一无二的标识符ID。ID的结构为ID(client, clock),即包含两个部分:客户端唯一ID client和逻辑时间戳clock。Item之间可以根据ID来比较逻辑先后关系。由此,我们获得了数学上严格的偏序结构。
每个Item都可以被单独序列化编码分发,CRDT算法保证只要每个客户端最终都能接收到全部的 item,那么不论客户端以何种顺序接收到这些 item,它们都能重建出完全一致的文档状态。
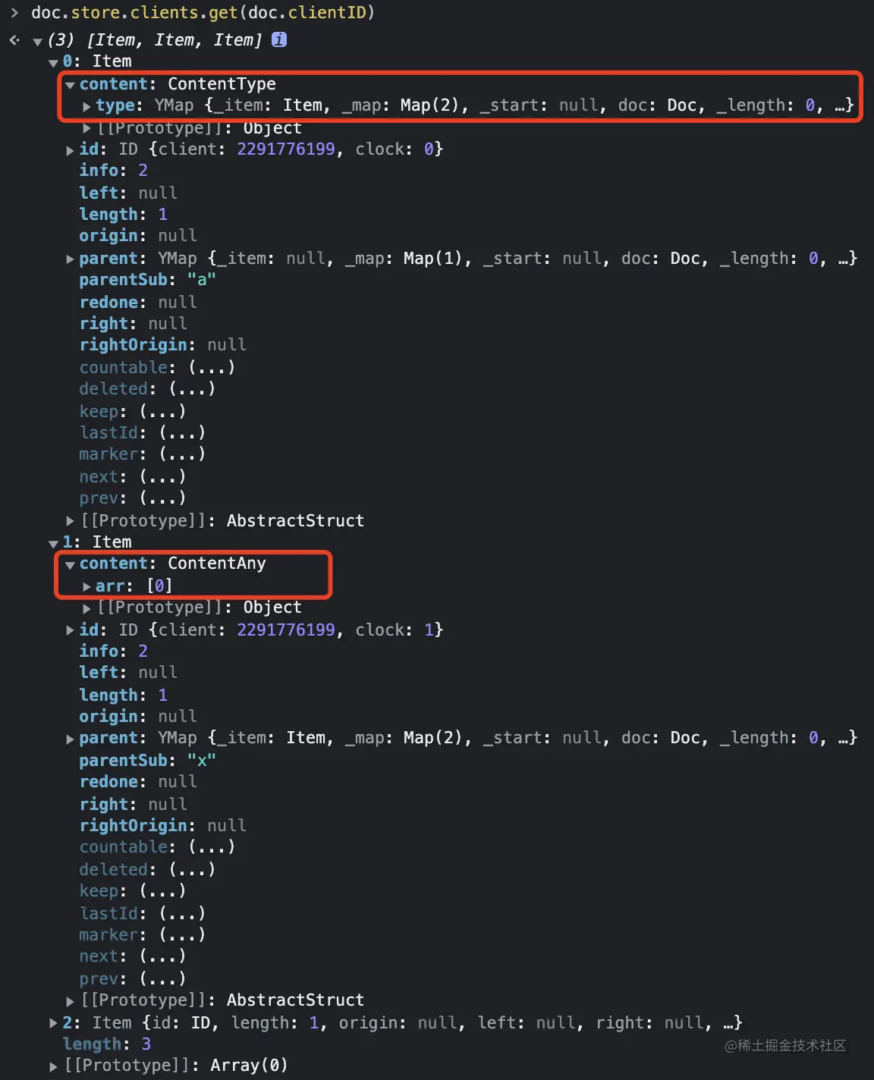
Yjs是YATA算法的工程化实现,Yjs为每个 client 分配一个扁平的 item 数组,相应的结构被称为 StructStore:
// 实践中可以用 doc.store.clients.get(doc.clientID) 查看
doc.store.clients: {
114514: [Item, Item, Item], // ...
1919810: [Item, Item, Item] // ...
}
复制代码
key是cilent ID,value是每个cilent的排序后的Item。Yjs内部按照client来给所有Item分类存放方便二分查找和操作。同时,每个Item也由前驱left 后继right以双向链表的形式连接在一起,从头到尾走完这个链表,就能得到最终的文档状态。
冲突处理
来看看YATA是如何解决并发冲突问题的:
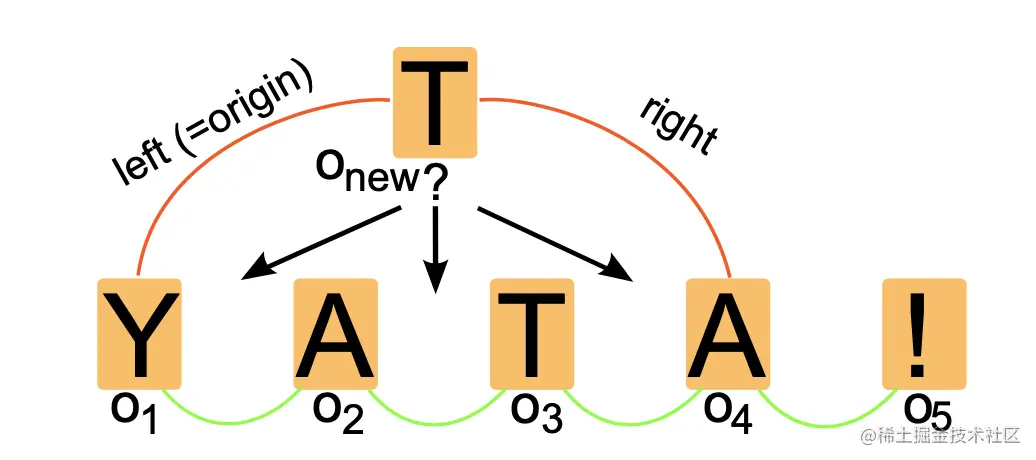
一个新的操作(也称为Item) Onew 要插入O1和O4之间,此时并发还产生了O2和O3的插入操作,因此Onew O2 O3三者形成了冲突操作序列 (the list of conflicting operations)。
我们上面说了,Item之间是通过ID排序的,因此这个序列如果满足以下三条规则,在数学上可以证明是严格全序的:
规则一:禁止互相冲突的操作之间有交叉连接的原点。允许的两种Case分别是:插入操作在其它操作和它的原始操作之间;一个操作的原点是另一个操作的后续。我们可以参照下图理解这句话,下图是被允许的两种情况。 规则二:当指定O1<O2时,不会存在另外一个操作比O2大同时比O1小。
规则三:当两个冲突的插入操作具有相同Origin时,用户ID小的操作在左侧。此规则参照了OT算法。
具体证明可以查阅后面给出的YATA算法论文。
也就是说,我们可以依据ID对冲突操作序列排序,只要确定了冲突操作的逻辑顺序,就得到了最终的状态。只要确保每个用户都接收到了所有的Item,不论接收的顺序如何,只要用这种方式解决冲突,最终都能得到相同的最终状态。这就是CRDT的 convergence(最终状态一致性)概念。
下面是确定一个操作 (Item) 在冲突操作序列中的位置的算法伪代码:
// Insert ’i’ in a list of
// conflicting operations ’ops ’.
insert(i, ops){
i . position = ops [0]. position
for o in ops do
// Rule 2:
// Search for the last operation // that is to the left of i.
if(o<i.origin
OR i.origin <= o.origin)
AND (o. origin != i . origin
OR o.creator o.origin do
// Breaking condition ,
// Rule 1 is no longer satisfied // since otherwise origin
// connections
break
}
历史回溯
CRDT中使用了链表的数据结构,而不是根据坐标定位,所以可以理解为完全没有「脏路径」问题;然后并发冲突问题也完全可以基于 Item的ID去解决;并且一份文档中所有的 item 结构都可以被持续存储下来。那么基于 CRDT 的方案中,实现 undos/redos 应该就比较简单了,只需要根据 CRDT 的数据结构的新增或者删除去实现 undos/redos 栈就可以有效解决问题。 假如进行了一个生成结构对象的操作,那么撤回的时候就把它标记删除即可。
网络同步
Yjs 也设计了配套的网络协议y-protocols。核心是分发序列化的Item,因为Item携带了前驱后继等引用信息,所以不能简单地直接序列化为JSON格式。
事实上,y-protocols使用了Uint8Array 形式的 update 数据编解码。YATA支持每个客户端离线编辑,并把操作记录在本地,客户端联网后,YATA会检查本地数据和共享数据的不同并完成数据同步。在同步文档状态时,Yjs 划分了两个阶段:
- 阶段一:某个客户端可以发送自己本地的 state vector,向远程客户端获取缺失的文档 update 数据。
- 阶段二:远程客户端可以使用各自的本地 clock 计算出该客户端所需的 item 对象,并进一步编码生成包含了所有未同步状态的最小 update 数据。
试一试
Vertex Collaboration (vertexvis.io) 基于Yjs实现的在线3D模型编辑器。
https://demos.yjs.dev Yjs官方开源的Demos:yjs/yjs-demos: A collection of demos for Yjs (github.com)
展望
CRDT 有着极佳的去中心化性质,它在 Web 3.0 时代或许有机会成为某种形式的前端基础设施。并且相对于经典的 OT,近年来 CRDT 的流行或许也属于一次潜在的范式转移(paradigm shift),这对前端开发者们意味着全新的机遇。
同时,CRDT比较适合来记录用户产生的各种事件的集合,因此将这些事件直接用于推荐系统的计算也是自然而然的事情。特别是对于很多大规模的企业,需要将用户的数据分布在多个数据中心,必须要实现读写两方面的高可用,特别是一些边缘计算的场景,可以利用CRDT的去中心化、离线、无冲突等特性实现用户操作数据的收集和同步。
拓展阅读
- Marc Shapiro, Nuno Preguiça, Carlos Baquero and Marek Zawirski, Conflict-free replicated data types (2011 正式定义 CRDT 的论文)
- Petru Nicolaescu, Kevin Jahns, Michael Derntl and Ralf Klamma, Near Real-Time Peer-to-Peer Shared Editing on Extensible Data Types ( YATA 论文)
- 多人协同编辑技术的演进 – 掘金 (juejin.cn)
- 基于CRDT的一种文档冲突算法 – 掘金 (juejin.cn)
- 探秘前端 CRDT 实时协作库 Yjs 工程实现 – 掘金 (juejin.cn)